 Dyrk.org
Dyrk.org{Linkedin} Faire du Publipostage à l’aide de la fonction « Recherche »

Bonjour à tous !
Aujourd’hui j’ai le cœur léger, j’ai enfin mis fin à 14 mois de pénibles échanges par avocat interposé avec mes ex-associé ! C’est terminé, j’ai enfin la tête hors de l’eau et je vais pouvoir avancer !
Je n’ai contractuellement pas le droit de vous raconter les détails trépidant de cette aventure, ni même de citer le nom de la société en cause, mais je vous le dis : c’est fini !
Aujourd’hui je vais pouvoir me concentrer sur l’avenir ! Notamment à l’aide de ma VAE qui me validera officiellement un niveau Bac + 4, grâce à 8 années d’expériences très concentrés tant sur des projets professionnels que personnels !
J’espère que vous appréciez un peu le nouveau format de mes articles et que l’ajout de vidéo de démonstration vous plait ! J’ai eu l’occasion de voir quelques personnes s’abonner à la chaîne et ça … c’est super chouette !
Je me tâte à ouvrir une boite postale pour les lecteurs parmi vous qui souhaiterais m’envoyer des bricoles pour l’écriture de mes articles ! Qu’en pensez-vous ? Qu’auriez vous envie de m’envoyer ?!?
J’avais prévu de faire un appels au don fin 2018, mais j’ai été assez pris et finalement j’ai laissé tomber …
Linkedin, nous voilà !
C’est donc là le sujet de l’article si vous avez bien lu le titre ! Il ne faudrait pas traîner trop sur l’introduction ^^
Alors voilà, j’étais entrain d’errer dans le couloir des idées d’articles foireuses …. lorsque soudain la lumière c’est allumé !
Une personne vient me voir et me demande de lui construire un outil qui permettrait … d’extraire des données Linkedin … pour ceux qui connaissent le sujet, il s’agit d’écrire un crawler !
L’objectif est bien entendu de réaliser une opération de publipostage !
Ni une ni deux, j’attaque donc l’écriture d’un script !
La recherche Linkedin
Linkedin, charge progressivement le contenu de ses pages, et met en place des protections assez sympa pour lutter contre les crawlers !
Il faudra donc réaliser un script qui simule un comportement humain, ni trop rapide, ni trop lent …
Qui génère des défilements de pages, pour charger le contenu, qui clic sur les boutons suivants, précédents, …
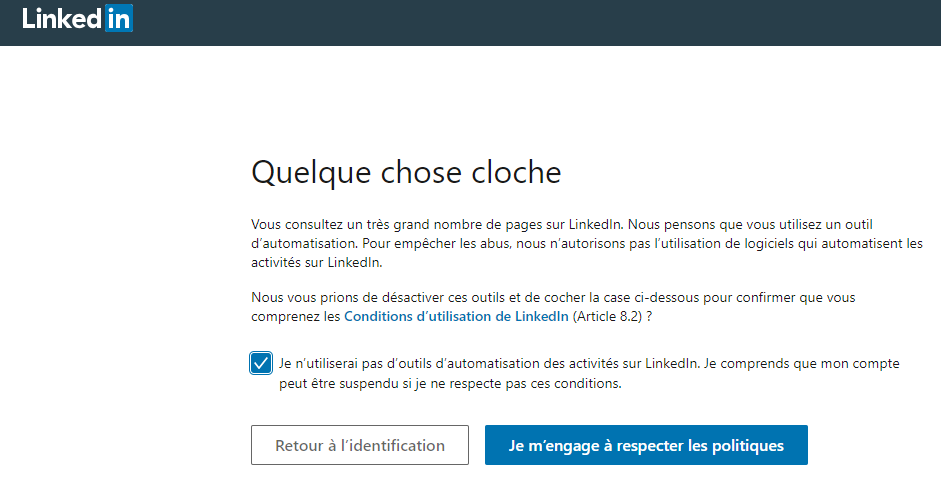 Néanmoins, comme vous le démontre la capture d’écran ci-dessus … Linkedin dispose du nombre de page que vous consultez … par heure / par jour .. ou par mois, il ne faut donc pas être trop gourmand ^^
Néanmoins, comme vous le démontre la capture d’écran ci-dessus … Linkedin dispose du nombre de page que vous consultez … par heure / par jour .. ou par mois, il ne faut donc pas être trop gourmand ^^
Pour obtenir la capture ci-dessus, je vous avoue que j’ai pas mal forcé, il s’agit là de plusieurs centaines de profils que mon script à consulter lors de mes différents tests !
Mon script va donc parcourir chaque page et extraire les liens vers les différents profils.
Pour chaque profil, je vais démarrer un traitement différé, celui-ci va donc parcourir des profils en arrière plan, pendant qu’il extrait les liens vers les profils.
Les profils Linkedin – #Partie Technique
C’est là que j’ai eu pas mal de fil à retordre …
Si vous êtes un peu curieux, vous pourrez regarder le code source de la page d’un profil Linkedin !
Toutes les données sont là … mais dans n’importe quel ordre dans des objets qui font références à d’autres objets, avec des identifiants d’objets, de position dans la page, des types de contenus ….
Les données sont exposées entre balise <code></code>, et sont au format JSON, vous pourrez donc faire une récupération de ce qu’il y a entre toutes les balises <code> et le parser, vous obtiendrez pour chacun, un objet … toutes les données que vous cherchez se trouvent dans la propriété « included » sous la forme d’un tableau d’objets …

En parcourant tous les objets contenus dans le tableau « included« , j’ai constaté que les données qui m’intéressaient « firstName« , « lastName« , « locationName » (‘Nom’,Prénom’, ‘localisation’) , possédait une propriétés $type dont la valeur se trouvait être l’une de celle-ci :
- com.linkedin.voyager.identity.profile.Profile
- com.linkedin.voyager.identity.profile.Position
- com.linkedin.voyager.identity.shared.MiniProfile
Lorsqu’il s’agit du nom et du prénom, il faut juste ignorer les données qui contiennent les termes suivant :
- Actu
- Récap
- Linkedin Récap
Quant à l’entreprise … il s’agit simplement de récupérer tous les objets qui contiennent la propriété « companyName » (nom de l’entreprise) en faisant un tri à l’aide des dates « startDate » « endDate » contenu dans l’objet à travers la propriété « timePeriod« .
Me concernant, j’ai simplement récupérer les dates les plus récentes, et lorsque je n’avais pas de date de fin, j’y mettait 2042 ;)
Script de téléchargement des résultats d’une recherche Linkedin
Pour utiliser le script suivant, il vous faudra réaliser les opérations suivantes dans cet ordre :
- Faites une recherche Linkedin
- Ouvrez la console développeur à l’aide de la touche F12 ou par « clic droit » > « inspecter »
- Copiez-collez le code ci-dessous
- Validez avec la touche « entrée«
- Patientez !
[pastacode lang= »javascript » manual= »%2F*%0A%09%09(c)%20Dyrk%20-%202019%20%2F%202020%0A%09%09Linkedin%20Search%20Extractor%20%0A*%2F%0A%0Avar%20results%20%3D%20%5B%5D%2C%20d%20%3D%20document%2C%20h%20%3D%20d.getElementsByTagName(‘html’)%5B0%5D%2C%20%0A%09AllowedType%20%20%3D%20%5B’com.linkedin.voyager.identity.profile.Profile’%2C’com.linkedin.voyager.identity.profile.Position’%2C%20’com.linkedin.voyager.identity.shared.MiniProfile’%5D%2C%0A%09endTreatments%20%3D%20function()%7B%0A%09%09%2F*%0A%09%09%09G%C3%A9n%C3%A9re%20un%20fichier%20CSV%20%20%C3%A0%20partir%20des%20donn%C3%A9es%20stock%C3%A9es%20dans%20la%20variables%20%20%22results%22%0A%09%09*%2F%0A%09%09setTimeout(function()%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20var%20doc%20%3D%20d.createElement(‘a’)%2C%20txt%20%3D%20%22%22%3B%0A%20%20%20%20%20%20%20%20%20%20%20results.map(profil%20%3D%3E%20%7B%0A%09%09%09%09if%20(!profil.firstName)%20return%20-1%3B%0A%09%09%09%09%5B’firstName’%2C’lastName’%2C’title’%2C’locationName’%2C’companyName’%2C’startDate’%2C’endDate’%5D.map(item%3D%3E%20(txt%2B%3D%20profil%5Bitem%5D%20%2B’%3B’))%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20txt%2B%3D%22%5Cn%22%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20%7D)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20doc.setAttribute(‘TARGET’%2C’BLANK’)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20doc.setAttribute(‘download’%2C’extract.csv’)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20doc.href%20%3D%20’data%3Atext%2Fcsv%2C’%2BencodeURIComponent(txt)%0A%20%20%20%20%20%20%20%20%20%20%20%20doc.click()%3B%0A%20%20%20%20%20%20%20%20%7D%2C%2010000)%3B%0A%09%09return%20console.log(‘termin%C3%A9%20-%20Enregistrement%20en%20cours’)%3B%0A%7D%2C%20scrollBottom%20%3D%20function(x)%7B%0A%09%2F*%0A%09%09La%20fonction%20scrollBottom%20s’appelle%20recursivement%0A%09%09mais%20temporise%20chacune%20de%20ses%20recursions%0A%09%09lorsqu’elle%20effectu%C3%A9%20x%20scroll%2C%20elle%20d%C3%A9marre%20le%20traitement%20collectResult%0A%09*%2F%0A%09h.scrollTop%20%3D%20%20h.scrollTop%20%2B%20250%3B%0A%09setTimeout(x%20%3C%3D%200%20%3F%20collectResult%20%3A%20scrollBottom.bind(null%2C%20–x)%2C%201000)%3B%0A%7D%2C%20collectProfilInfo%20%3D%20function(url)%7B%0A%09%2F*%0A%09%09Effectue%20une%20requ%C3%AAte%20ajax%20sur%20le%20profil%2C%20et%20collecte%20les%20diff%C3%A9rentes%20infos%20%0A%09%09Nom%2C%20Pr%C3%A9nom%2C%20localisation%2C%20derni%C3%A8re%20entreprise%2C%20…%20%0A%09*%2F%0A%09profil%20%20%3D%20new%20XMLHttpRequest()%3B%0Aprofil.addEventListener(‘load’%2C%20(function(url%2Ce)%7B%0A%09var%20profil%20%3D%20%7B%7D%2C%20dom%20%3D%20new%20DOMParser()%2C%20test%20%3D%20false%3B%0A%20%20%20%20doc%20%3D%20dom.parseFromString(e.target.response%2C%20’text%2Fhtml’)%3B%0A%20%20%20%20datas%20%3D%20doc.getElementsByTagName(‘code’)%3B%0A%09for%20(var%20i%20in%20datas)%7B%0A%09%09if%20(typeof%20datas%5Bi%5D!%3D%20’object’)%20continue%3B%0A%09%09if%20(datas%5Bi%5D.textContent.indexOf(‘firstName’)%20%3D%3D-1%20%20%26%26%20datas%5Bi%5D.textContent.indexOf(‘lastName’)%20%3D%3D-1)%20continue%3B%0A%09%09data%20%3D%20JSON.parse(datas%5Bi%5D.textContent).included%3B%0A%09%09data.map((el)%20%3D%3E%20%5B’firstName’%2C’lastName’%2C%20’locationName’%2C%20’companyName’%5D.map(key%3D%3E%7B%0A%09%09%09if%20(el%5Bkey%5D%20%20%26%26%20AllowedType.indexOf(el%5B’%24type’%5D)%20!%3D%20-1%20%26%26%20%0A%09%09%09%09%5B’actu’%2C’r%C3%A9cap’%2C%20’linkedin’%2C’linkedin%20r%C3%A9cap’%5D.indexOf(el%5Bkey%5D.toLowerCase())%3D%3D-1)%7B%0A%09%09%09%09%09if%20(%5B’firstName’%2C’lastName’%5D.indexOf(key)%20!%3D-1%20%26%26%20el%5B’publicIdentifier’%5D%20!%3D%20%2F.*%5C%2F(.*%3F)%5C%2F%24%2F.exec(url)%5B1%5D)%0A%09%09%09%09%09%09%20return%20el%3B%0A%09%09%09%09%09profil%5Bkey%5D%20%3D%20el%5Bkey%5D%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20%09%7D%0A%09%09%09if%20(el%5Bkey%5D%20%26%26%20%20key%20%3D%3D%20’companyName’)%7B%20%0A%09%09%09%09el.timePeriod.endDate%20%3D%20typeof%20el.timePeriod.endDate%20!%3D%20%22undefined%22%20%3F%20el.timePeriod.endDate%20%3A%20%7B%22year%22%3A2042%2C%22month%22%3A12%7D%0A%09%09%09%09el.timePeriod.startDate.month%20%3D%20typeof%20el.timePeriod.startDate.month%20!%3D%20%22undefined%22%20%20%3F%20el.timePeriod.startDate.month%20%3A%2001%3B%0A%09%09%09%09startDate%20%3D%20el.timePeriod.startDate.year%20%2B%20(el.timePeriod.startDate.month%20%3E%209%20%3F%20el.timePeriod.startDate.month%20%3A%20’0’%2Bel.timePeriod.startDate.month)%3B%0A%09%09%09%09endDate%20%09%3D%20el.timePeriod.endDate.year%20%2B%22%22%2B%20(el.timePeriod.endDate.month%20%3E%209%20%3F%20el.timePeriod.endDate.month%20%20%3A%20’0’%2Bel.timePeriod.endDate.month)%3B%0A%09%09%09%09if%20(!profil.endDate%20%7C%7C%20parseInt(profil.endDate)%20%3C%20parseInt(endDate))%7B%0A%09%09%09%09%09profil%5Bkey%5D%20%3D%20el%5Bkey%5D%3B%0A%09%09%09%09%09profil.startDate%20%3D%20startDate%3B%0A%09%09%09%09%09profil.endDate%20%20%20%3D%20endDate%3B%0A%09%09%09%09%09profil.title%09%20%3D%20el.title%0A%09%09%09%09%7D%0A%09%09%09%7D%0A%09%09%09return%20el%3B%0A%20%20%20%20%20%20%20%20%7D))%3B%0A%09%7D%3B%0A%09results.push(profil)%3B%0A%09console.log(profil)%3B%0A%09%7D).bind(null%2C%20url))%3B%0A%09profil.open(‘GET’%2C%20url)%3B%0A%09profil.send(null)%3B%0A%7D%2C%20collectResult%20%3D%20function()%7B%0A%09%2F*%0A%09%09%22collectResult%22%20permet%20de%20r%C3%A9cup%C3%A9rer%20les%20liens%20de%20chacun%20des%20profils%20d’une%20page%20de%20recherche%0A%09%09Pour%20chaque%20lien%20r%C3%A9colt%C3%A9%20il%20d%C3%A9marre%20un%20traitement%20diff%C3%A9r%C3%A9%20de%20collecte%20des%20infos%20du%20profil%20%22collectProfilInfo%22%0A%09%09Le%20traitement%20s’arr%C3%AAte%20sur%20la%20derni%C3%A8re%20page%2C%20et%20appelle%20%22endTreatments%22%20qui%20g%C3%A9n%C3%A9rera%20un%20fichier%20csv%0A%09%0A%09*%2F%0A%09%20var%20lst%20%3D%20d.getElementsByClassName(‘search-result__wrapper’)%2C%20urlProfil%3B%0A%20%20%20%20for%20(var%20i%20in%20lst)%7B%0A%20%20%20%20%20%20%20%20if%20(typeof%20lst%5Bi%5D%20!%3D%20’object’%20%7C%7C%20lst%5Bi%5D.getAttribute(‘done’))%20continue%3B%0A%09%09try%7B%0A%09%09%09urlProfil%20%3D%20lst%5Bi%5D.getElementsByTagName(‘a’)%5B0%5D.getAttribute(‘href’)%3B%0A%09%09%09if%20(urlProfil%20!%3D%20’%23′)%20setTimeout(collectProfilInfo.bind(null%2C%20urlProfil)%2C%201000)%3B%0A%20%20%20%20%20%20%20%20%09lst%5Bi%5D.setAttribute(‘done’%2C’done’)%3B%0A%20%20%20%20%20%20%20%20%7D%20catch%20(e)%7B%7D%3B%0A%20%20%20%20%7D%0A%09bt%20%3D%20d.getElementsByClassName(‘artdeco-pagination__button–next’)%5B0%5D%3B%0A%09try%20%7B%0A%09%09listPage%20%3D%20d.getElementsByClassName(‘artdeco-pagination__indicator%20artdeco-pagination__indicator–number’)%3B%0A%09%09lastPage%20%3D%20listPage%5BlistPage.length-1%5D.textContent.trim()%3B%0A%09%09currPage%20%3D%20%2Fpage%3D(%5B0-9%5D*)%2F.exec(d.location)%3B%0A%09%09if%20((currPage%20%3F%20currPage%5B1%5D%20%3A%201)%3D%3D%20lastPage)%20return%20endTreatments()%3B%0A%09%09bt.click()%3B%0A%20%20%20%20%7D%20catch%20(e)%7B%0A%09%09console.log(%22Error%20%22%2Ce)%3B%0A%09%09%20return%20endTreatments()%3B%0A%20%20%20%20%7D%0A%09setTimeout(scrollBottom.bind(null%2C%204)%2C%201000)%3B%0A%09%0A%7D%3B%0A%2F*%20%0ALinkedin%20charge%20les%20pages%20progressivement%0AIl%20faut%20donc%20scroller%20jusqu’en%20bas%20pour%20obtenir%20la%20page%20enti%C3%A8re.%0AscrollBottom%20va%20g%C3%A9n%C3%A9rer%20x%20scroll%0A*%2F%0AscrollBottom(4)%3B » message= » » highlight= » » provider= »manual »/]
Vidéo de démonstration
Pensez à prendre 5 minutes pour vous abonnez si vous appréciez le fait que j’ajoute du contenu vidéo.
Je ne touche pour l’instant pas d’argent avec Youtube, mais peut-être un jour cela me permettra d’en récupérer quelques revenus pour investir dans du matériels pour mes articles ;)
Deviner des adresses emails
Souvent les adresses mails d’une entreprise sont formatée selon une certaine norme.
Si je m’appel Dave Hill et que je bosse pour l’entreprise bidule, on peut imaginer :
- d.hill@bidule.com
- dave.hill@bidule.com
- dh@bidule.com
- dave-hill@bidule.com
- dave.h@bidule.com
- ….
Quelques recherches sur Internet, vous permettrons de trouver une ou deux adresses mails de l’entreprise dont vous pourrez vous inspirer pour deviner le bon formatage d’adresse email.
Législation
Bien que le challenge de cet article soit divertissant, il est toutefois à noter qu’il est interdit de faire du crawling à des fins commerciales sans le consentement de la personne que vous allez démarcher.*
Conclusion
Linkedin, freine assez bien l’utilisation de bot, cet effort est à poursuivre, mais vos données sont accessibles publiquement, et n’importe qui avec un peu (beaucoup) d’analyse … pourra récupérer vos données et les utiliser à des fins commerciales.
Souvent lorsque l’on me démarche, et que je ne vois pas la trame de fond Linkedin, je prend le temps de répondre à la personne en l’interrogeant sur la manière dont il s’est procuré mon contact !
D’ailleurs, petite technique pour savoir si un chasseur de tête vous a repéré par le bouche à oreille ou par Linkedin … mettez un faux nom / prénom sur Linkedin, et sur tous les sites professionnels.
Bonne journée à tous !