 Dyrk.org
Dyrk.org[OpenShift] Gérer facilement et dynamiquement un parc de Docker

Hello tout le monde,
Aujourd’hui … je vous offre un article assez conséquent sur OpenShift.
Je suis encore assez novice sur le sujet, mais j’espère en tout cas que cet article vous permettra de découvrir dans les grandes lignes ce qu’est ce produit et surtout à quoi il sert.
Il y aura dans un premier temps des rappels basiques, un peu de vulgarisation, et enfin quelques lignes de commandes avec des références vers de la documentation officielle.
Je vous souhaite en tout cas une très bonne lecture, et j’espère que cet article vous plaira !
Le choix de Docker
Là où je travail, c’est la croix et la bannière pour disposer d’une machine virtuelle afin d’y mettre son projet …
C’est encore plus compliqué d’être exigeant sur les performances de ladite machine, tant sur le plan « stockage« , que sur sa « puissance » !
Les machines « puissantes » sont là pour « mutualiser » …
Nous allons y mettre une, deux, trois … quatre …voire cinq … applications !
Celles-ci auront probablement du mal à ne pas se marcher les unes sur les autres …
Soit pour écrire sur le disque …
Soit pour communiquer sur le réseau …
… etc …
Créant alors des conflits (port, droit, …) à tous azimuts !
Lorsqu’une machine n’arrive plus à suivre … rebelote, on repart sur le problème de disponibilité des machines …
Imaginez donc une discussion de vendeur de tapis :
– On cherche une machine avec plus de performance
– Combien ?
– Euh je dirais bien 10 Go d’espace disque et 2 Go de mémoire vive ?
– Je t’en propose 5 Go .. auxquels j’ajoute 1Go de mémoire vive … car la demande est forte en ce moment …
– Oui mais mon application a besoin de ….
– Bon ok 6 Go de stockage, c’est ma dernière offre !
– Vendu ..
Aussi, nous réfléchissons de plus en plus à nous tourner vers le monde fabuleux du Docker !
Petit rappel sur ce qu’est Docker : Créer des images « Docker »
Docker c’est avant tout l’application avant son environnement, ce qui réduit considérablement l’espace disque et les performances qu’on pourrait attendre d’une VM !
Docker permet également de mutualiser plusieurs applications sur une même machine MAIS en les isolants les unes des autres !
Supprimant ainsi, les divers conflits de port réseaux, de droit d’écriture, … etc …
Un super Hyperviseur Docker
OpenShift est une solution payante de Redhat …
La version communautaire est gratuite ici :
https://github.com/openshift/origin
Mais vous pouvez bosser avec un « équivalent » gratuitement chez vous qui s’appelle MiniShift :
https://github.com/minishift/minishift
Il vous permettra de surveiller chacune de vos applications Docker, mais pas seulement, vous pourrez carrément les gérer, réaliser des déploiements, supprimer des applications, allouer de la ressource, mettre des bridages et plus encore !
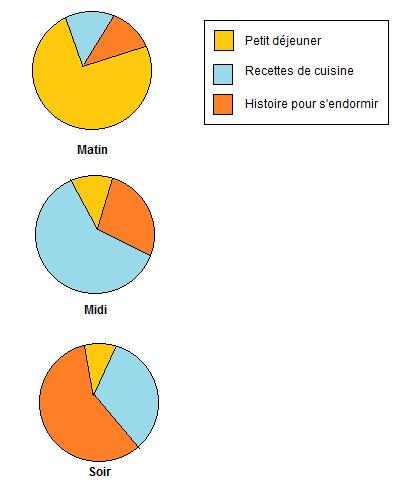
Imaginez que vous ayez 3 applications Web:
- Application 1 : Petit-déjeuner, une application qui va beurrer vos tartines pour vous
- Application 2 : Recette de cuisine
- Application 3 : Histoires pour s’endormir
Répartition de la charge
Indéniablement le matin, vous allez avoir beaucoup d’utilisateur de l’application 1.
Le midi et le soir, vous aurez plutôt des utilisateurs de l’application 2.
Quant au soir, c’est surtout l’application 3 qui sera utilisée.
OpenShift (et Kubernetes qui est inclus dans le produit) va donc allouer en fonction de la demande les ressources nécessaires !
Au lieu d’avoir une énorme machine, avec beaucoup de puissance …
OpenShift va créer allouer dynamiquement les ressources d’une ou plusieurs machines.
Mise à disposition automatique
Il est possible de dire … pour mon application « Petit déjeuner« , je souhaite lui mettre à disposition entre 1 et 10 machines (que l’on appelle des « pods« ) ….
L’application « Petit déjeuner » … si elle est fortement sollicitée va donc utiliser progressivement une, deux, trois .. etc … pods, qu’elle va d’abord « créer » et sur lesquels elle va déployer nos images dockers, jusqu’à pouvoir « respirer » un peu !
Lorsque l’application devient moins sollicitée, tous les pods inutilisés vont se libérer !
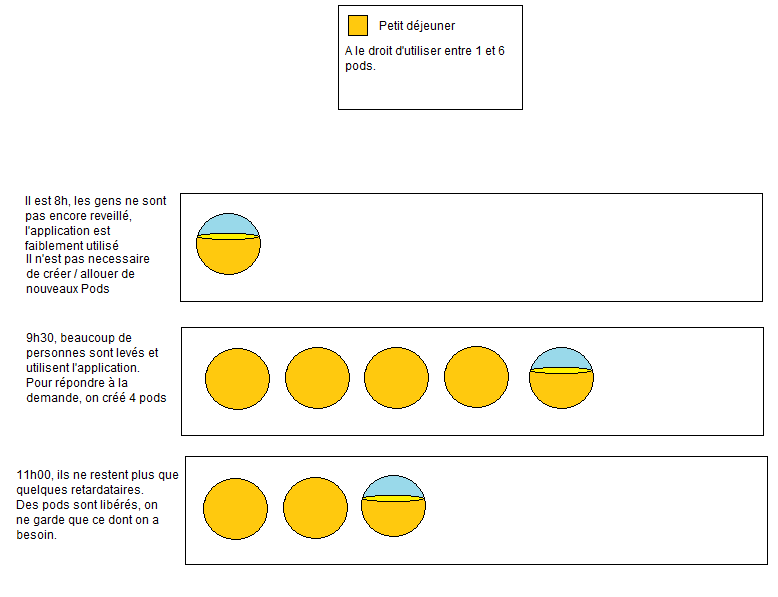
J’ai ici représenté des bocaux remplis de sable (nos utilisateurs), selon si j’ai beaucoup ou peu d’utilisateurs, OpenShift (selon les limites que je lui ai fixé : entre 1 et 10 pods) va créer ou détruire des pods !
Limitation des ressources et Qualité de service
Il est également possible de brider les pods.
À l’image d’une machine virtuelle qui serait fortement sollicitée … tellement que le système serait complément instable avec un CPU à 100%, une mémoire vive saturée, et un fichier de swap plein !
Il est donc possible de dire avec OpenShift :
> je souhaite que l’utilisation des images dockers sur mes pods n’excède pas 80% de CPU
Comme ça chaque pods créé ne pourra dépasser les 80% de CPU … lorsqu’il atteindra cette limite, un nouveau pods sera automatiquement créé (cf. chapitre « Mise à disposition automatique« )
Permettant de conserver des pods opérationnels sans qu’il ne soit débordé.

Entrons dans la technique
Si les explications ci-dessus n’ont pas été suffisamment claires pour vous, il n’est pas nécessaire de poursuivre sur cette partie-là.
Si au contraire vous maîtrisez le sujet, et que j’ai dit par inadvertance une bêtise, n’hésitez surtout pas à partager / corriger au travers d’un commentaire.
Nous allons d’abord refaire une petite passe sur des sujets annexes à Docker.
Les images « Docker«
Après avoir réalisé un projet Docker, vous allez logiquement faire un « build » :
docker build –no-cache -t mon-image-docker:v1
Le –no-cache vous permettra de prendre en compte tous les éléments du projet sans s’appuyer sur des résidus de cache.
Le -t va ajouter un tag (référence / appellation) sur votre « build ».
Vous pourrez ensuite l’exporter.
Ce qui vous permettra par exemple :
- De la partager,
- De créer des images hors ligne « from scratch«
- De l’importer dans un « repository locale » ou dans un « repository distant«
docker save mon-image-docker:v1 -o mon-image.tar
Ici nous allons donc exporter notre build sous la forme d’une archive « .tar »
Les « repository«
Lorsque vous créez une image Docker, vous réalisez un fichier « Dockerfile« .
Celui-ci commencera par « FROM : <quelquechose> »
Le « <quelquechose> » c’est soit « scratch » … , auquel cas vous construirez une image en partant de rien.
Soit le nom d’une « image base », qui est une image docker existante, à laquelle que vous souhaitez ajouter des customisations.
Lorsque vous démarrer votre projet docker avec image existante, celle-ci va être récupérée sur un repository.
Il y a 2 types de « repository » … le local (installé sur votre machine) et le distant (si vous avez un espace dédié sur un serveur).
Importer une image Docker dans un Repository
Si vous disposez d’une image docker, il vous est possible de l’importer dans votre « repository locale » de la manière suivante:
docker load –input mon-image-docker.tar
Si vous disposez d’un repository distant :
Vous pourrez l’exporter vers votre « repository distant » de la manière suivante :
On crée un tag distant :
docker tag mon-image-docker:v1 <mon repository distant>/mon-image-docker:v1
Connexion au repository :
docker login « http(s)://<mon repository distant>/ »
Pour terminer, on envoie tout ça au repository :
docker push <mon repository distant>/mon-image-docker:v1
OpenShift
Lorsque vous aurez installé le produit OpenShift (ou Minishift), vous pourrez créer des « projets ».
Pour la suite, je vous invite à aller cliquer sur le petit point d’interrogation en haut à droite, afin d’y sélectionner « command line tools »
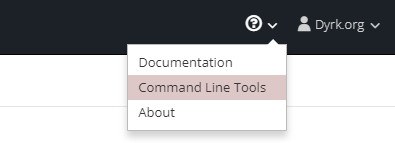
Vous aurez sur cette page, quelques lignes de commande explicative, sur comment se connecter, créer un projet, sélectionner un projet, ….
La ligne de commande d’OpenShift, fonctionne avec le binaire « oc« , téléchargeable depuis un lien sur cette même page :
Pour se connecter, il vous faudra cliquer sur le bouton à l’extrémité de la ligne « oc login »

Il vous faudra ensuite copier cette ligne dans votre terminal :

Ici, j’avais déjà un projet, et vu que c’était mon seul projet, j’ai directement été « connecté » sur ce projet.
Importer une image docker dans OpenShift
Ce projet est vide, pour y ajouter votre image docker et créer une première application ( application est le jargon OpenShift pour dire container), il faudra saisir la ligne suivante :
oc new-app –docker-image=<mon repository distant>/mon-image-docker:v1
–docker-image, indiquera le « registry » et le tag de l’image docker à récupérer.
Il faudra ensuite patienter un petit peu … votre image va être chargée …
Une fois le chargement terminé, vous devriez obtenir un « Success » !
C’est cool, ça veut dire que votre image Docker est importée, et que vous disposez à présent d’une application !
Pour plus d’informations sur la création d’application (registry local, git, …etc …) :
https://docs.openshift.com/enterprise/3.2/dev_guide/new_app.html
Les variables d’environnement
Si votre image Docker démarre avec des variables d’environnement :
docker run -e NOM=Henri-e PRENOM=Dupont-e AGE=26 mon-image-docker:v1
Il faudra ajouter à notre application ces variables !
Maintenant que nous avons importé notre image docker, voyons un peu l’identifiant OpenShift de celle-ci :
oc get dc
Cette ligne de commande, va me retourner les applications que j’ai dans ce projet.
Ici on voit que je n’ai que mon application « mon-image-docker »

Nous allons donc lui ajouter nos variables de la manière suivante :
oc env dc/mon-image-docker NOM=Henri
Nous pouvons visualiser la / les variables de notre application comme ceci :
oc env dc/mon-image-docker –list
Si vous souhaitez un peu plus d’infos, sur comment ajouter / supprimer /modifier / consulter des variables d’environnement c’est par ici :
https://docs.openshift.com/enterprise/3.0/dev_guide/environment_variables.html
Déploiement d’application / image Docker & création de pod
Nous avons importé une image Docker qui est chez OpenShift une « application ».
Nous lui avons associé des variables d’environnement.
Il ne nous reste plus maintenant qu’à la déployer !
oc rollout latest dc/mon-image-docker
Le déploiement devrait démarrer suite à cette commande.
![]()
Là aussi, il est possible de faire un paquet de chose :
https://docs.openshift.com/container-platform/3.6/dev_guide/deployments/basic_deployment_operations.html#start-deployment
Créer des « routes«
Pour accéder à votre application, vous avez la possibilité de créer des « routes », de donner un « hostname » et un « port » à OpenShift et hop, il vous servira le tout sur un plateau d’argent
Pour le coup, l’interface graphique sera probablement plus parlante :
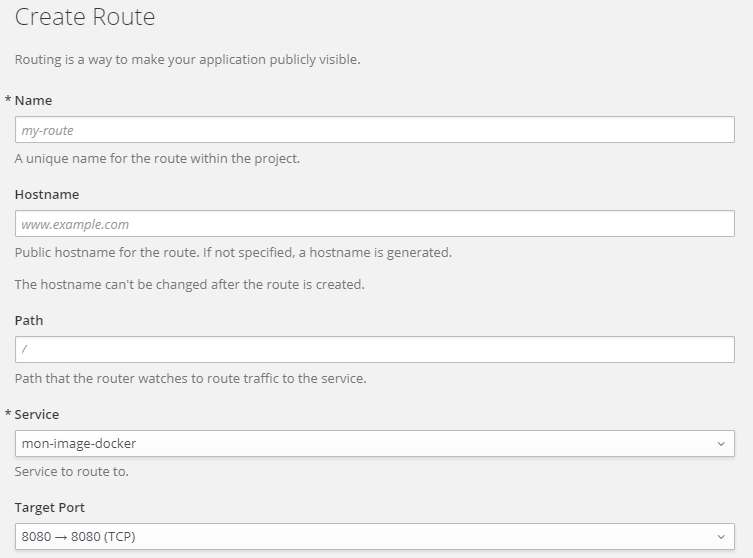
Et hop, vous aurez un beau formulaire, ou vous pourrez donner un nom à votre « route », une adresse Web, le choix de l’application à afficher sur cette « route », et le port de votre choix (dépendant de l’application bien entendu)
Mais pour ceux qui voudront passer par la ligne de commande, let’s go c’est par ici :
https://docs.openshift.com/container-platform/3.3/dev_guide/routes.html
Supprimer des pods, des applications, des routes, … avec OpenShift
Nous arrivons au bout du tunnel !
Nous avons :
- Créé une image docker
- Importé notre image docker dans un registry
- Créé un projet OpenShift
- Importé une image docker sous la forme d’une application
- Créé des variables d’environnement
- Déployé une application sur un pod
Nous sommes des héros !
Bref ça fait beaucoup d’info pour un seul homme, mais si vous êtes courageux, j’aurais encore 2/3 sujets à voir avec vous !
Avant de supprimer quelques choses dans OpenShift, il faut en connaitre sa référence :
oc get all
Cette commande vous sortira l’ensemble des éléments que vous avez le droit de voir, et de gérer ;)
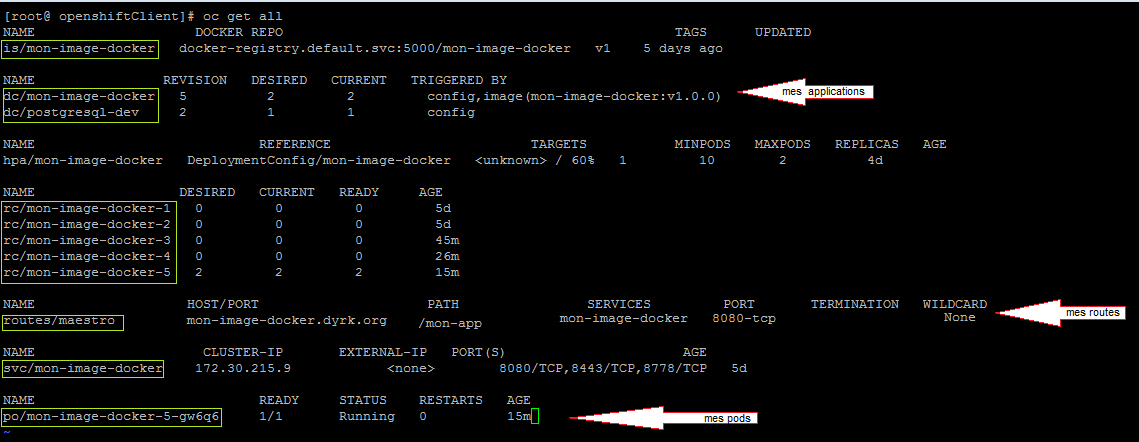
Okey, donc là nous avons donc tous les éléments OpenShift qui nous concerne.
J’ai encadré en vert les « références » de ces « objets »
Pour supprimer un « objet » OpenShift, on procède ainsi :
oc delete <référence de l’objet>
Exemple :
![]()
Accéder à la console d’un pod
Okey, vous souhaitez vous connecter directement sur une application déployée sur un pod pour je ne sais quelle raison !
C’est faisable :
oc rsh <référence du pod>
Petite démo :![]()
Et vous voilà connecté sur votre pod, à vous de jouer !
AutoScaling ?
À vos souhaits ! Vous n’avez pas éternué ?
Vous ne pigez pas ce mot ?
Okey, donc si vous avez jeté un œil à ma longue introduction sur OpenShift, vous comprendrez mieux.
L’autoscaling c’est ce qui permet de gérer dynamiquement votre parc de pod …
Vous créez des règles sur une application :
Tu as 1 pod, mais au besoin, si tu es débordé tu peux créer jusqu’à 10 pods pour te soulager, attention je veux que tu fonctionnes correctement, donc ne dépasses pas les 60% de ton CPU …
Et hop en une ligne de commande :
oc autoscale –min=1 –max=10 –cpu-percent=60 dc/mon-image-docker
–min le nombre minimum de pod
–max le nombre maximum de pod
–cpu-percent le pourcentage maximum d’utilisation du CPU avant la création d’un nouveau pod
La commande autoscale, permet de créer des contraintes !
Et ensuite, on laisse la magie opérer !
Plus d’info ici :
https://docs.openshift.com/enterprise/3.2/dev_guide/pod_autoscaling.html
Conclusion
Un article très très long je vous l’accorde, j’ai mis pas mal de temps à l’écrire, et encore plus à essayer de le simplifier.
Je suis encore tout jeune dans le monde de l’openShift, il est possible qu’il y ait des erreurs de dialectiques, de formulation, voire même des choses erronées (je n’espère pas :s)
J’espère en tout cas que vous aurez pu découvrir ce beau produit, et qu’il vous servira ;)