 Dyrk.org
Dyrk.org[Linkedin] – Collecter tous les profils d’une recherche

Linkedin, Viadeo et d’autres encore, sont aujourd’hui les premiers outils utilisés par les recruteurs pour trouver des profils intéressants.
J’ai donc pris le temps suite à quelques demandes d’internautes et une anecdote personnelle récente, de vous développer un petit script qui vous permettra de télécharger sur votre ordinateur, tous les profils d’une recherche !
Sous la forme de données exploitables et manipulables !
Comment ça marche ? (Néophytes et non Néophytes)
Ce script est téléchargeable ici : linkedinMassiveCrawler
Pour ce faire il suffit de vous rendre sur la page de recherche de personne Linkedin :
https://www.linkedin.com/search/results/people/
Faites une recherche dessus.
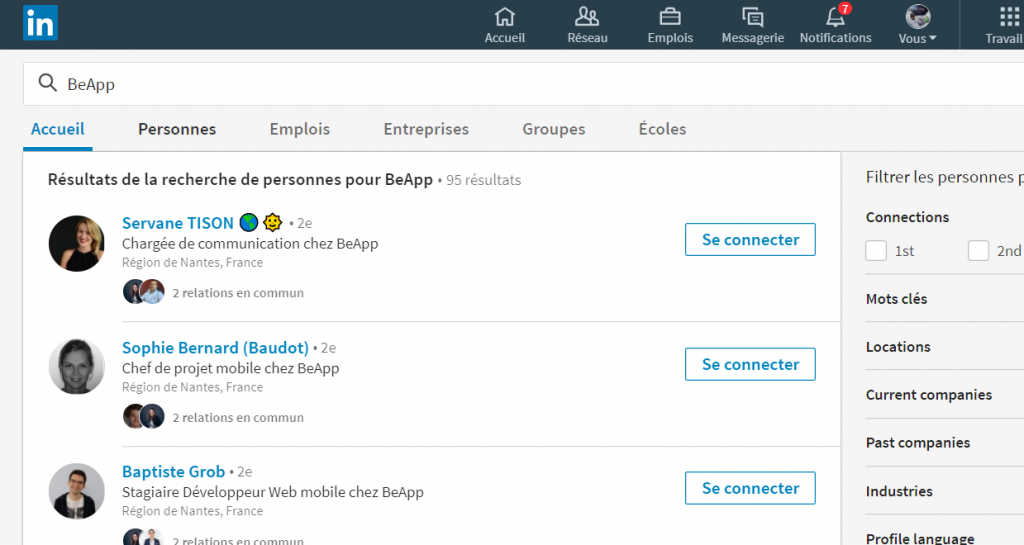
Ensuite, il vous faudra ouvrir la console développeur (touche F12 de votre clavier, petit onglet « console) et copier le contenu du script dedans.
Enfin il vous faudra valider avec la touche entrée.
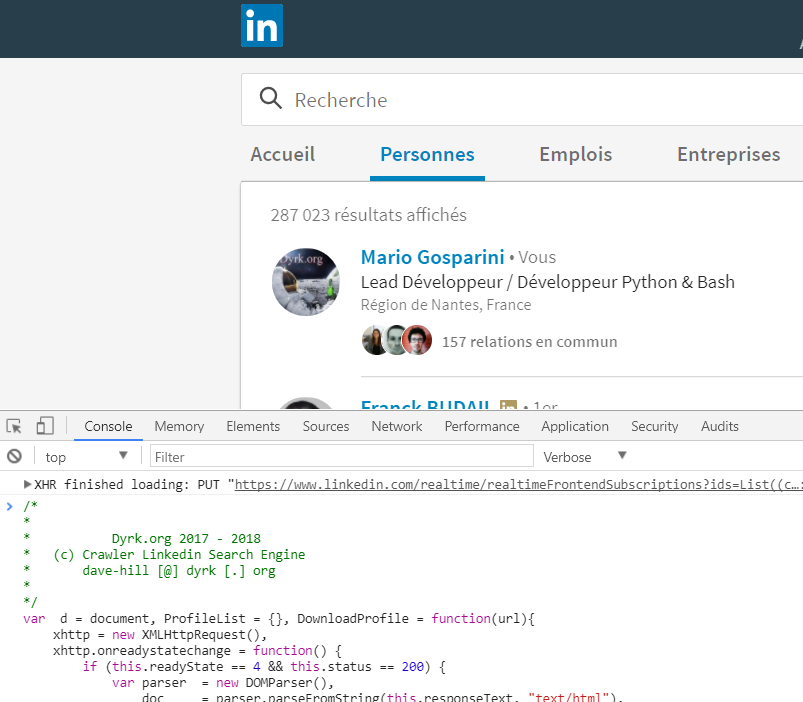
Le script va alors parcourir tous les résultats de votre recherche, consultera chaque profil, et fera également défiler chaque page de la recherche.
Chaque action sera espacée par un court délai de 2 secondes, Linkedin n’aimant pas trop les crawlers, celui-ci reconnaître facilement une activité anormale … au hasard, lorsque 200 profils sont consultés en moins d’une minute ^^
Au bout de quelques minutes (selon la taille de la recherche …)
Votre navigateur vous demandera s’il a le droit de télécharger sur votre ordinateur plusieurs fichiers …. il vous faudra bien sur accepter !
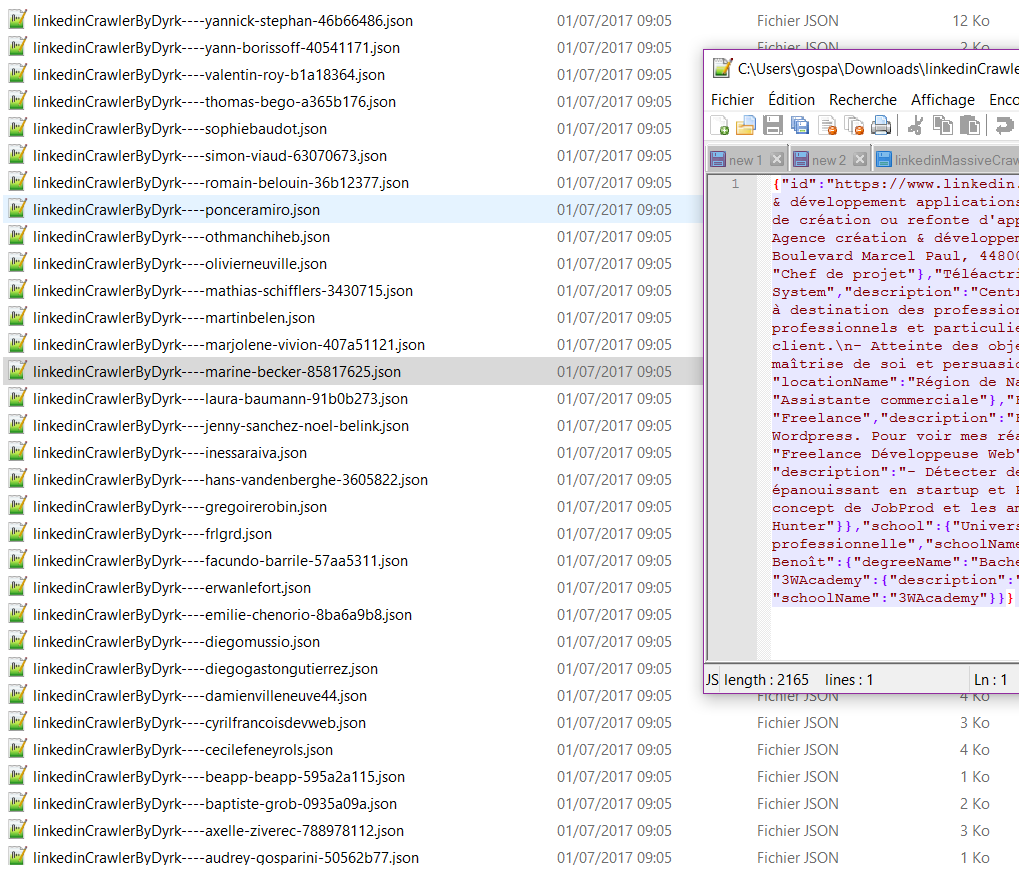
Chacun des fichiers téléchargés contiendra l’expérience et les formations des utilisateurs au format JSON.
Si vous n’êtes pas développeurs et que vous ne savez pas trop exploiter cela, il vous faudra copier coller le contenu de ce fichier dans des outils comme celui-ci :
http://jsbeautifier.org/
Ces données, lorsqu’elles sont correctement indentées, sont très facilement lisibles

Vous pourrez ensuite consulter tranquillement en étant hors-ligne (par exemple dans un train) des profils intéressants !
Et éventuellement les passer dans des moulinettes intelligentes (si vous avez sous la main des développeurs) pour rendre plus pertinentes ces données :)
Techniquement
Les liens vers les profils
Récupération de tous les liens d’une page de recherche :
document.getElementsByTagName(‘a’)
Vérification de la légitimité d’un lien
L’url d’un profil est construite comme ça : linkedin.com/in/nom-prenom-identifiant/
Il suffit donc de vérifier si les liens de la page rentrent dans ce cas
/linkedin\.com\/in\/([A-Za-z0-9^_\-]{0,30})\/.*?/.exec(lien_de_la_page)
Extraction des données d’une page Linkedin
Lorsque vous regardez le code source d’une page de profile linkedin vous remarquez tout un tas de balise de ce genre là :
<code style= »display: none » id= »bpr-guid-1060784″>
{"data":{"companies":[],"$deletedFields":["paidProducts","postJobsEnabled"],"memberGroup":"FREE","$type":"com.linkedin.voyager.common.Nav","$id":"M8x5UY0Zt6eGdBCiy+iKhA==,root"},"included":[]}
</code>
De prime abord, on remarque clairement qu’il s’agit là de données au format JSON.
Celles-ci sont altérées par des caractères HTML (Ex : ")
Il nous faudra alors transformer ce beau tas de m*** en données exploitables.
donnees_encodees = « {"data":{"companies … »;
decodeur = document.createElement(‘textarea’);
decodeur.innerHTML = donnees_encodees;
donnees_decodees = decodeur.value;
Les données, une fois « décodées », devraient ensuite ressembler à ça :
{« data »:{« companies »:[], »$deletedFields »:[« paidProducts », »postJobsEnabled »], »memberGroup »: »FREE », »$type »: »com.linkedin.voyager.common.Nav », »$id »: »M8x5UY0Zt6eGdBCiy+iKhA==,root »}, »included« :[]}
Ahah, on est d’accord, c’est bien plus lisible !
la donnée qui nous intéresse c’est « included« , celle-ci contient un tableau.
Il vous faudra parcourir chaque élément « <code> » pour parcourir la partie included

En parcourant « included », vous aurez un certain nombre d’éléments …
Il vous suffira de ne conserver, que ceux qui contiennent « title » ou « schoolName ».
Passez à la page suivante de la recherche
Sur chaque page de recherche, vous trouverez en bas un bouton « suivant »

Sauf, lorsqu’il n’y a plus de résultat.
Il suffit donc de vérifier que le bouton est là :
if (document.getElementsByClassName(‘next-text’)[0])
// Le bouton est présent
else
//Le bouton n’est plus présent
Si le bouton est présent, il pourra alors charger la page suivante en cliquant dessus
document.getElementsByClassName(‘next-text’)[0].click();
Conclusion
Voilà les amis, vous êtes prêt pour devenir des usines à collecter les données :p
Attention :
encore une fois, il s’agit là d’un « hack », il est possible que Linkedin corrige et qu’un jour cela ne fonctionne plus.
Pour ma petite communauté que j’aime tant :
Beaucoup d’entre vous ont remarqué que je n’écrivais plus beaucoup ces dernières semaines.
Peu d’entre vous le savent, mais il n’y a qu’une personne derrière ce blog « perso », car oui, malgré la quantité d’articles je ne suis pas blogueur professionnel, je n’affiche même pas de publicité.
Il m’arrive parfois d’avoir la page blanche, soit parce que j’ai une période personnelle qui s’y prête et que je n’ai pas l’âme à écrire, soit tout simplement parce que je n’ai pas de sujet en tête.
Sachant que j’essaie au mieux de trouver des petites choses à écrire, qui ne sont pas en copier-coller 15.000 fois sur l’internet ;)
En tout cas je souhaite vous remercier de votre fidélité et de vos petits messages soucieux de la santé du blog. Merci à tous !
Voilà, sinon je serais présent au DevFest durant les 2 jours, si jamais ça vous branche de se prendre un verre là-bas : https://devfest.gdgnantes.com/